

vLLM and PagedAttention: A Comprehensive Overview
Easy, Fast, and Cheap LLM Serving

Easy, Fast, and Cheap LLM Serving
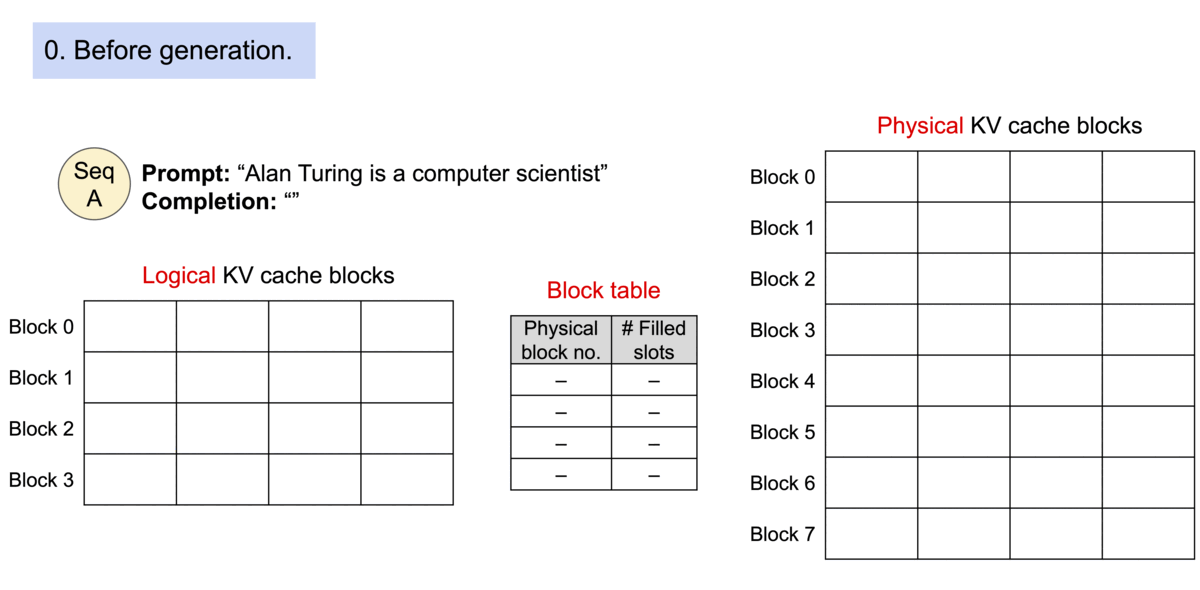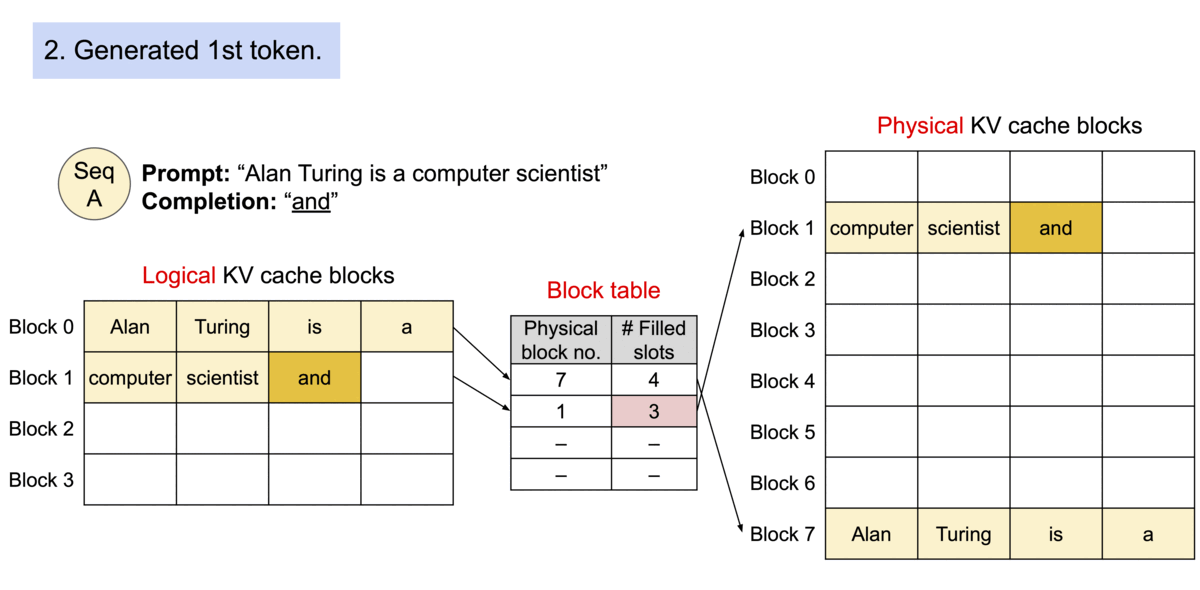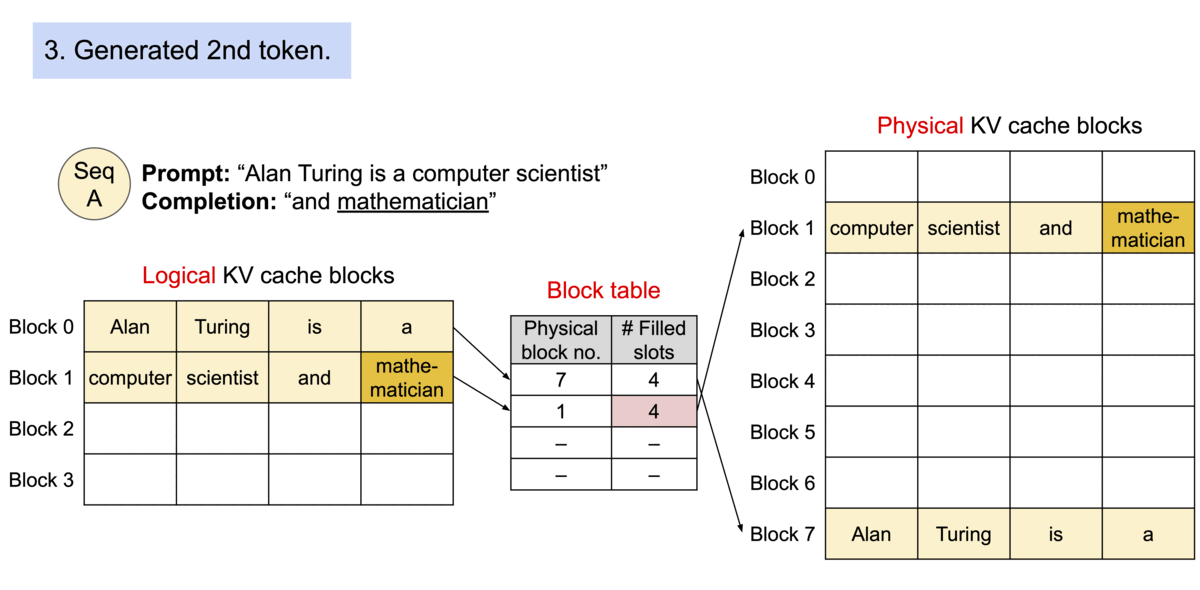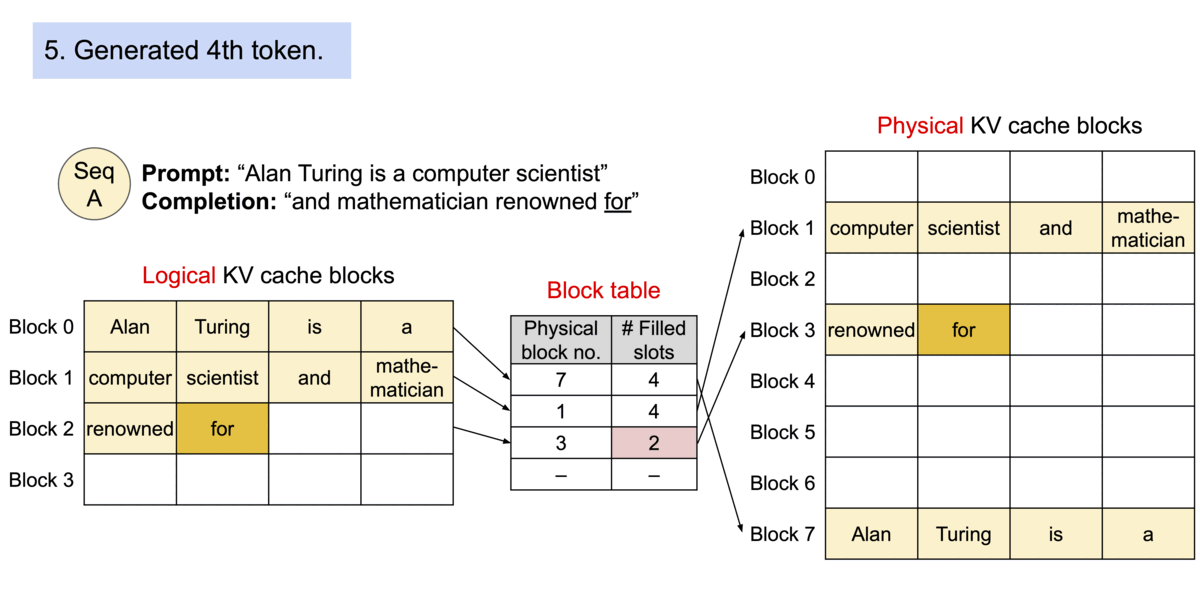
vLLM is a library designed to enhance the efficiency and performance of Large Language Model (LLM) inference and serving. Developed at UC Berkeley, vLLM introduces PagedAttention, a novel attention algorithm that significantly optimizes memory management for attention keys and values. This innovation not only boosts throughput but also enables continuous batching of incoming requests, fast model execution with CUDA/HIP graph, and supports various decoding algorithms including parallel sampling and beam search. vLLM is compatible with both NVIDIA and AMD GPUs, and it seamlessly integrates with popular Hugging Face models, making it a versatile tool for developers and researchers alike.
PagedAttention: The Key Technique
PagedAttention is the heart of vLLM’s performance enhancements. It addresses the critical issue of memory management in LLM serving by partitioning the KV cache into blocks, allowing for non-contiguous storage of keys and values in memory. This approach not only optimizes memory usage, reducing waste by up to 96%, but also enables efficient memory sharing, significantly reducing the memory overhead of complex sampling algorithms. PagedAttention’s memory management strategy is inspired by the concept of virtual memory and paging in operating systems, offering a flexible and efficient way to manage memory resources.
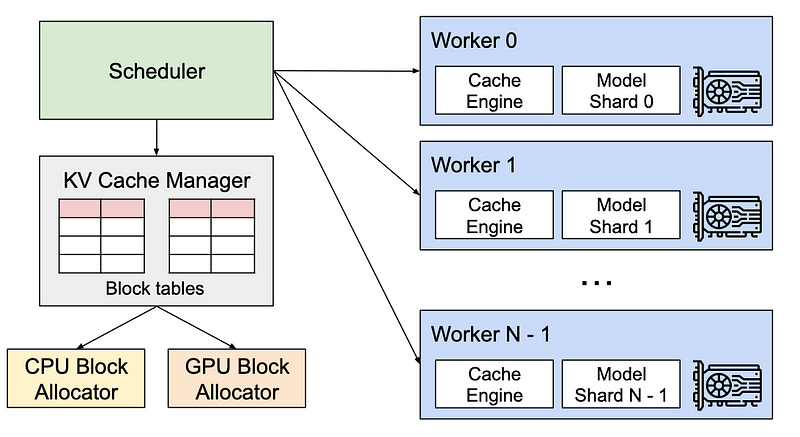
vLLM’s Features and Capabilities
High Throughput and Memory Efficiency: vLLM delivers state-of-the-art serving throughput, making it an ideal choice for applications requiring high performance and low latency.
Continuous Batching of Requests: vLLM efficiently manages incoming requests, allowing for continuous batching and processing.
Fast Model Execution: Utilizing CUDA/HIP graph, vLLM ensures fast execution of models, enhancing the overall performance of LLM serving.
Quantization Support: vLLM supports various quantization techniques, including GPTQ, AWQ, SqueezeLLM, and FP8 KV Cache, to further optimize model performance and reduce memory footprint.
Optimized CUDA Kernels: vLLM includes optimized CUDA kernels for enhanced performance on NVIDIA GPUs.
Tensor Parallelism Support: For distributed inference, vLLM offers tensor parallelism support, facilitating scalable and efficient model serving across multiple GPUs.
Streaming Outputs: vLLM supports streaming outputs, allowing for real-time processing and delivery of model outputs.
OpenAI-Compatible API Server: vLLM can be used to start an OpenAI API-compatible server, making it easy to integrate with existing systems and workflows.
Documenation and Paper
GitHub - vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for…
A high-throughput and memory-efficient inference and serving engine for LLMs - vllm-project/vllmgithub.com
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
GitHub | Documentation | Papervllm.ai
Integration with Hugging Face Models
vLLM seamlessly supports a wide range of Hugging Face models, including Aquila, Baichuan, BLOOM, ChatGLM, DeciLM, Falcon, Gemma, GPT-2, GPT BigCode, GPT-J, GPT-NeoX, InternLM, Jais, LLaMA & LLaMA-2, Mistral, MPT, OLMo, OPT, Orion, Phi, Qwen, Qwen2, StableLM, Starcoder2, and Yi. This broad compatibility ensures that vLLM can be used with a vast array of LLM architectures, making it a versatile tool for developers and researchers working with different model types.
# 1. vLLM - Offline Batch Inference
from vllm import LLM
# Sample prompts.
prompts = ["Hello, my name is", "Capital of France is"]
# Create an LLM with HF.
llm = LLM(model="gpt2")
# Generate texts from the prompts.
outputs = llm.generate(prompts)Getting Started with vLLM
To get started with vLLM, you can install it via pip and use it for both offline inference and online serving. For offline inference, you can import the LLM class from vLLM and generate texts from prompts. For online serving, vLLM can be used to start an OpenAI API-compatible server, allowing you to query the server in the same format as the OpenAI API. This ease of use, combined with vLLM's powerful features, makes it an attractive option for developers looking to leverage LLMs in their applications.
Google Colaboratory
Edit descriptioncolab.research.google.com
# 2. vLLM - Fast-API based server for Online Serving
# OpenAI API-compatible server
# Server
! python -m vllm.entrypoints.openai.api_server
--host 127.0.0.1
--port 8888
--model meta-llama/Llama-2-7b
# Client
!curl http://127.0.0.1:8888/v1/completions
-H "Content-Type: application/json"
-d '{
"model": "meta-llama/Llama-2-7b",
"prompt": "Paris is a",
"max_tokens": 7,
"temperature": 0
}'LMSYS introduced Vicuna chatbot models, which are now used by millions in Chatbot Arena. Initially, FastChat used HF Transformers for serving, but as traffic surged, vLLM was integrated to handle up to 5x more traffic, significantly improving throughput by up to 30x over the initial HF backend.
Conclusion
vLLM, powered by PagedAttention, represents a significant advancement in LLM serving, offering a solution that is not only fast and efficient but also cost-effective. Its practical applications, such as serving Vicuna chatbot models, showcase its potential to revolutionize how LLMs are used across various industries. With vLLM, the future of LLM serving looks promising, offering high throughput and low latency without compromising on performance
Connect with me on Linkedin
Find me on Github
Visit my technical channel on Youtube
Thanks for Reading!