



Open-Source Vision Language Models (VLMs) in Multimodal AI
Curated List - Open source - Multimodal AI

Introduction to Multimodal AI and Vision Language Models (VLMs)
Multimodal AI refers to systems capable of processing and interpreting multiple forms of data—text, images, audio, and video. By combining these modalities, AI can develop a deeper understanding of complex information. Vision Language Models (VLMs) represent a subset of this field, focusing on processing visual data (images, videos) in conjunction with textual information.
In recent years, open-source VLMs have gained significant traction, challenging proprietary models with their performance and capabilities. This shift has democratized access to advanced multimodal AI, enabling researchers and developers to further explore and push the boundaries of AI.
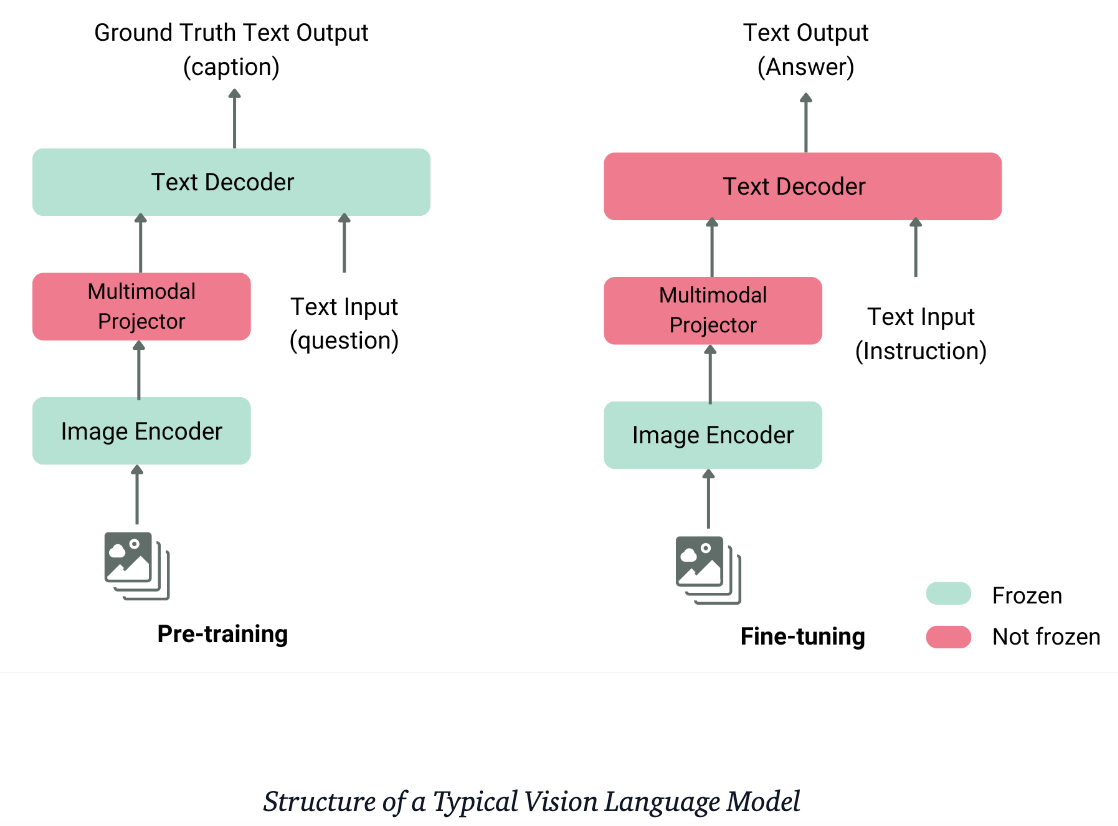
Image: HuggingFace
Key Players in Open-Source Vision Language Models
Several open-source VLMs have emerged, each bringing unique capabilities to the table. Below ar
e some notable models:
Llama 3.2 Vision
An extension of Meta's Llama model, Llama 3.2 Vision is designed for image-text tasks, excelling in areas like captioning and image-based question answering.
Model Architecture
Llama 3.2-Vision builds upon the Llama 3.1 text-only model, an auto-regressive language model leveraging an optimized transformer architecture. The fine-tuned versions of the model utilize supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for safety and helpfulness. To handle image recognition tasks, Llama 3.2-Vision integrates a separately trained vision adapter with the pre-trained Llama 3.1 language model. This adapter includes a series of cross-attention layers that process image encoder representations and feed them into the core language model.
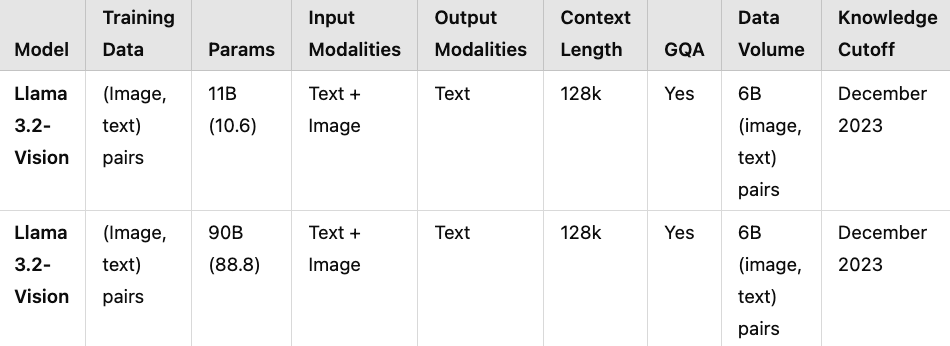
Parameters: 11B, 90B
Strengths: Visual content generation, chart, and diagram understanding
Limitations: Math-heavy tasks, language support restricted to English
Learn more about Llama 3.2 Vision
NVLM 1.0
Developed by UC Berkeley, NVLM 1.0 is tailored for multimodal large language model tasks such as OCR and multimodal reasoning.

Figure : NVLM-1.0 offers three architectural options: the cross-attention-based NVLM-X (top), the hybrid NVLM-H (middle), and the decoder-only NVLM-D (bottom). The dynamic high-resolution vision pathway is shared by all three models. However, different architectures process the image features from thumbnails and regular local tiles in distinct ways.
Strengths: OCR, high-resolution image handling, multimodal reasoning
Special Features: NVLM-D (OCR), NVLM-H (hybrid reasoning)
Molmo
Developed by the Allen Institute for AI, Molmo is a state-of-the-art VLM excelling across multiple benchmarks.It offers state-of-the-art performance across various benchmarks. An impressive model that can "point" to elements within images and perform complex multimodal tasks.

Figure :The Molmo architecture follows the simple and standard design of combining a language model with a vision encoder. Its strong performance is the result of a well-tuned training pipeline and our new PixMo data.
Parameters: 1B, 7B, 72B
Strengths: Pointing in images, benchmark-leading performance
Limitations: Struggles with transparent images, requires preprocessing
Qwen2-VL
Qwen2-VL extends VLM capabilities to complex object relationships in scenes, with strong video analysis performance.
Model Architecture
A significant architectural enhancement in Qwen2-VL is the introduction of Naive Dynamic Resolution support. Unlike its predecessor, Qwen2-VL can handle images with arbitrary resolutions by mapping them to a dynamic number of visual tokens. This ensures alignment between the model's input and the intrinsic information in the images, providing a more human-like visual processing experience. As a result, the model can efficiently process images of varying clarity and size.

Multimodal Rotary Position Embedding (M-ROPE): Decomposes positional embedding into parts to capture 1D textual, 2D visual, and 3D video positional information, enhancing its multimodal processing capabilities.

Strengths: Top-tier visual understanding, video comprehension
Limitations: Lacks built-in moderation, struggles with spatial reasoning
Pixtral
A 12-billion parameter model from Mistral, Pixtral is designed for both image and text processing, excelling in instruction-following tasks.
Architecture
Variable Image Size: Pixtral is optimized for both speed and performance. It features a new vision encoder that natively supports variable image sizes:
Images are passed through the vision encoder at their native resolution and aspect ratio, converting them into image tokens for each 16x16 patch.
These tokens are flattened into a sequence, with special [IMG BREAK] and [IMG END] tokens placed between rows and at the image’s end.
The [IMG BREAK] tokens help the model distinguish images with different aspect ratios, even when they have the same number of tokens.
This approach enables Pixtral to effectively process complex high-resolution diagrams, charts, and documents while maintaining fast inference speeds for smaller images like icons, clipart, and equations.

Final Architecture:
Pixtral is powered by a vision encoder trained from scratch to handle variable image sizes efficiently.
The final architecture consists of two main components:
Vision Encoder – This component tokenizes images.
Multimodal Transformer Decoder – It predicts the next text token based on a sequence of text and images.

Pixtral is trained to predict text tokens using interleaved image and text data, allowing the model to process any number of images of arbitrary sizes within its large context window of 128K tokens.
Strengths: Multi-image processing, native resolution handling
Features: Context window of 128,000 tokens
Comparison Chart


Technical Aspects of Open-Source VLMs
Open-source VLMs leverage innovative techniques to enhance multimodal processing, including:
Dynamic Resolution Handling: Models like Qwen2-VL handle arbitrary image resolutions, offering a human-like processing experience by dynamically mapping images into visual tokens.
Multimodal Rotary Position Embedding (M-ROPE): A technique that improves the ability of models to understand 1D textual, 2D visual, and 3D video positional information.
Tile-based Dynamic High-Resolution Image Processing: NVLM 1.0 boosts high-resolution image processing, particularly for multimodal reasoning and OCR tasks.
Production-Grade Multimodality: NVLM 1.0 showcases enhanced text-only performance post-multimodal training, illustrating the benefits of multimodal data in LLMs.
Dataset Quality and Diversity: Research suggests that dataset quality, rather than scale, significantly impacts pretraining success.
Challenges and Future Directions
While open-source VLMs have made great strides, challenges remain:
Math-Heavy Tasks: Many VLMs continue to struggle with tasks requiring high-level mathematical reasoning.
Handling Transparent Images: Models like Molmo face difficulties when processing images with transparency, necessitating advanced preprocessing techniques.
Ethical Considerations: Ensuring that VLMs have built-in moderation and safeguards is crucial, especially for models like Qwen2-VL, which currently lack such features.
Conclusion
The rise of powerful open-source VLMs marks a pivotal moment in the field of multimodal AI. By harnessing these models, we can push the boundaries of human-AI interaction, solving complex, multimodal challenges. The future of multimodal AI is bright, and it will be exciting to see how these models evolve in real-world applications.
Connect with Me
If you have any inquiries, feel free to reach out via message or email.
Connect with me on Linkedin
Find me on Github
Visit my technical channel on Youtube
Very informative
Glad it helped:)