

Chapter 1 - Introduction to NLP
Understanding of NLP and its potential applications

Natural language processing (NLP) is a field of computer science that deals with the interaction between computers and human language. NLP research has made significant progress in recent years, and it is now possible to develop systems that can understand, generate, translate, and even write human-quality text. It has become a hot topic in AI research because of its many potential applications, such as text generation, chatbots, and text-to-image applications.Recent advancements in NLP have led to a revolution in the ability of computers to understand human languages. These advancements have also allowed computers to understand programming languages and even biological and chemical sequences that resemble language. The latest NLP models are now able to analyze the meanings of input text and generate meaningful, expressive output. This means that computers can now understand and respond to human language in a more natural way.
In this article, we will provide an introduction to NLP and its applications. We will discuss the basic concepts of NLP, such as tokenization, stemming, and tagging. We will also introduce some of the most common NLP tasks, such as machine translation, sentiment analysis, and text summarization.
The goal of this article is to give you a basic understanding of NLP and its potential applications. By the end of this article, you will be able to identify the different components of an NLP system and understand the challenges involved in developing these systems.
In this article, we will cover the following topics,:
What is NLP? Definition and scope
Why does NLP matter?
Applications of NLP and Historical Context: Real-world uses, Evolution and milestones
How does NLP work?
Challenges and Limitations of NLP: Technical hurdles and complexities
Further Resource : popular NLP datasets, libraries, and online courses
What is NLP? Definition and scope
Natural language processing (NLP) is a branch of artificial intelligence that deals with the interaction between computers and human (natural) languages. As a branch of artificial intelligence, NLP uses machine learning to process and interpret text and data. Natural language recognition and natural language generation are types of NLP.It encompasses a wide range of tasks, including understanding and generating human language, translating languages, and summarizing text. NLP has become increasingly important in recent years as the amount of data available in the form of text and speech has grown exponentially. NLP has existed for more than 50 years and has roots in the field of linguistics. It has a variety of real-world applications in a number of fields, including medical research, search engines and business intelligence.
What is natural language processing used for?
Natural language processing applications are used to derive insights from unstructured text-based data and give you access to extracted information to generate new understanding of that data. Natural language processing examples can be built using Python, TensorFlow, and PyTorch.
NLP serves various essential roles across diverse industries. In the realm of customer sentiment analysis, NLP employs entity analysis to identify and label specific fields within documents and communication channels, offering valuable insights into customer opinions and facilitating the discovery of product and User Experience (UX) enhancements. For receipt and invoice understanding, NLP extracts entities, such as dates and prices, enabling the recognition of patterns between requests and payments. Document analysis benefits from custom entity extraction, streamlining the identification of domain-specific entities within documents without the need for labor-intensive manual analysis. Content classification involves categorizing documents by common entities, customized domain-specific entities, or over 700 general categories, aiding in tasks like trend spotting and marketing content extraction. In healthcare, NLP enhances clinical documentation, supports data mining research, and expedites automated registry reporting, thereby contributing to the acceleration of clinical trials. In finance, it automates tasks like customer service chatbots, fraud detection, and sentiment analysis of financial news. Legal applications involve analyzing legal documents, summarizing case law, and generating legal contracts. In education, NLP creates personalized learning experiences, assesses student writing, and generates adaptive learning materials. For government use, NLP analyzes public opinion, summarizes government reports, and automates administrative tasks, showcasing its versatility and significance across a spectrum of industries.

Why Does Natural Language Processing (NLP) Matter?
Natural language processing is a crucial part of everyday life, and it's becoming even more important as language technology is being applied to a wide range of industries, including healthcare and retail. Conversational agents like Amazon's Alexa and Apple's Siri rely on NLP to understand user inquiries and provide answers. GPT-4, a sophisticated NLP system, is capable of generating high-quality text on various topics and powering chatbots that can hold meaningful conversations. Google utilizes NLP to enhance its search engine results, while social media platforms like Facebook employ it to detect and block hate speech. While NLP is becoming increasingly sophisticated, there's still much room for improvement. Current systems can be biased and inconsistent, and they sometimes behave erratically. However, machine learning engineers have numerous opportunities to apply NLP in ways that will become increasingly essential to society.
NLP encompasses a broad range of subfields, each of which focuses on a particular aspect of language processing. Some of the most important subfields of NLP include:
Natural language understanding (NLU): This subfield focuses on the ability of computers to understand the meaning of human language. This includes tasks such as parsing, which involves breaking down text into its constituent parts (e.g., words, phrases, sentences), and semantic analysis, which involves extracting the meaning of the text.
Natural language generation (NLG): This subfield focuses on the ability of computers to generate human-like text. This includes tasks such as machine translation, which involves translating text from one language to another, and text summarization, which involves generating a concise overview of a piece of text.
Speech recognition: This subfield focuses on the ability of computers to understand human speech. This includes tasks such as transcribing audio recordings into text and controlling devices with voice commands.
Text-to-speech synthesis: This subfield focuses on the ability of computers to generate human-like speech. This includes tasks such as converting text into audio recordings and creating avatars that can speak.

Information Extraction: This field is concerned with the extraction of semantic information from text, which includes tasks such as named-entity recognition, coreference resolution, and relationship extraction.
Ontology Engineering: This field studies the methods and methodologies for building ontologies, which are formal representations of a set of concepts within a domain and the relationships between those concepts.
Statistical Natural Language Processing: This subfield includes statistical semantics, which establishes semantic relations between words to examine their contexts, and distributional semantics, which examines the semantic relationship of words across a corpora or in large samples of data.
Historical Context and Applications of NLP: Evolution , Milestones and Real-world uses
History and Milestones
The early history of NLP is marked by the work of Swiss linguist Ferdinand de Saussure, who described language as a system of relationships. In 1950, Alan Turing proposed the Turing test as a way to measure a machine’s ability to exhibit intelligent behavior equivalent to, or indistinguishable from, that of a human. This led to the development of NLP as a field of study.
The 1960s saw the development of early NLP systems, including ELIZA, which could simulate a conversation with a human. However, these systems were limited in their ability to understand and generate natural language. In the 1980s, there was a shift in NLP towards the use of machine learning algorithms. This led to significant improvements in the accuracy of NLP systems.
In the 1990s, the development of statistical NLP models further enhanced the field. These models were able to handle large amounts of text data and make more nuanced linguistic distinctions. In the 2000s, there was a resurgence of interest in NLP, driven by the availability of large amounts of data and advances in computing power. This led to the development of neural network models, which are now the state-of-the-art in NLP.

As in the above diagram, NLP has a rich history that can be traced back to the early days of computer science. Some of the key milestones in the history of NLP include:
1950: Alan Turing publishes his seminal paper, "Computing Machinery and Intelligence," which introduces the Turing test, a benchmark for evaluating machine intelligence.
1957: George Miller published his paper, "The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information," which highlights the limitations of human short-term memory and has implications for NLP research.
1960s: The development of statistical methods and machine learning algorithms leads to significant advances in NLP.
1980s: The rise of personal computers and the availability of large datasets fuel further progress in NLP.
2000s: The development of deep learning techniques revolutionizes NLP, enabling computers to achieve human-level performance in many tasks.
2020s: Large language Models, language model notable for its ability to achieve general-purpose language generation. LLMs acquire these abilities by learning statistical relationships from text documents during a computationally intensive self-supervised and semi-supervised training process.
Applications Area
Search engines: NLP is used to understand the queries that users enter into search engines and to return relevant results.
Virtual assistants: NLP is used to power virtual assistants such as Siri, Alexa, and Google Assistant. These assistants can understand natural language commands and respond in a way that is helpful and informative.
Machine translation: NLP is used to translate text from one language to another. This is a valuable tool for businesses that operate internationally and for people who want to read or communicate with people who speak different languages.
Sentiment analysis: NLP is used to analyze the sentiment of text, which is the attitude or opinion that the author expresses. This is a valuable tool for businesses that want to understand their customers' feedback and for social media analysts who want to track trends in public opinion.
Text summarization: Text summarization is the task of condensing lengthy documents into shorter, concise summaries that capture the key points of the original text. This is often done by identifying the most important sentences and phrases, and then rephrasing them in a more concise way. Text summarization is a valuable tool for quickly understanding the content of long documents, and it is used in a variety of applications, including news articles, research papers, and business reports.
Named entity recognition (NER): Named entity recognition is the task of identifying and extracting important entities like people, places, organizations, and dates from text. This is important for a variety of applications, such as search engines, social media analysis, and machine translation. For example, a search engine could use NER to identify the names of people, places, and organizations in user queries, and then provide more relevant search results.
Speech recognition: Speech recognition is the task of converting spoken language into text. This is a critical technology for a variety of applications, including voice assistants, dictation software, and call centers. For example, a voice assistant could use speech recognition to understand user commands, and then perform the desired actions.
Chatbots: Chatbots are computer programs that simulate conversation with human users. They are typically used to provide customer service, answer questions, and provide information. Chatbots are becoming increasingly sophisticated, and they are now able to engage in natural conversations with humans.
Question answering (QA): Question answering is the task of answering user questions based on text or knowledge bases. This is a valuable tool for accessing information quickly and easily. For example, a QA system could be used to answer questions about a book, a website, or a database.
Information retrieval (IR): Information retrieval is the task of finding relevant information from large amounts of text. This is a critical task for search engines, libraries, and other information systems. IR systems use a variety of techniques, such as indexing, ranking, and relevance feedback, to identify the most relevant documents for a given query.
Text generation: Text generation is the task of creating human-like text, such as poems, code, scripts, and musical pieces. This is a complex task that requires a deep understanding of language and the ability to generate creative text formats. Text generation is used in a variety of applications, such as machine translation, chatbots, and creative writing tools.
Linguistic analysis: Linguistic analysis is the study of the structure and meaning of human language. This includes the study of syntax, semantics, and pragmatics. Linguistic analysis is used to develop natural language processing (NLP) systems, and it is also used to study the evolution of language and the relationship between language and thought.
In addition to the above applications, NLP is also used in a variety of other fields, such as:
Law:Used to analyze legal documents, identify relevant information, and extract legal concepts.
Finance:Used to analyze financial data, identify trends, and make predictions.
Marketing: Used to analyze customer data, personalize marketing messages, and understand customer sentiment.
How Does Natural Language Processing (NLP) Work?
NLP models work by finding relationships between the constituent parts of language — for example, the letters, words, and sentences found in a text dataset. NLP architectures use various methods for data preprocessing, feature extraction, and modeling. Some of these processes are:
Data Preprocessing
Before a model deals with text for a particular task, the text usually needs some preparation. This is called data preprocessing, and it's important for the model to work well. Data-centric AI, a growing approach, focuses on this step. Various techniques are used in data preprocessing:

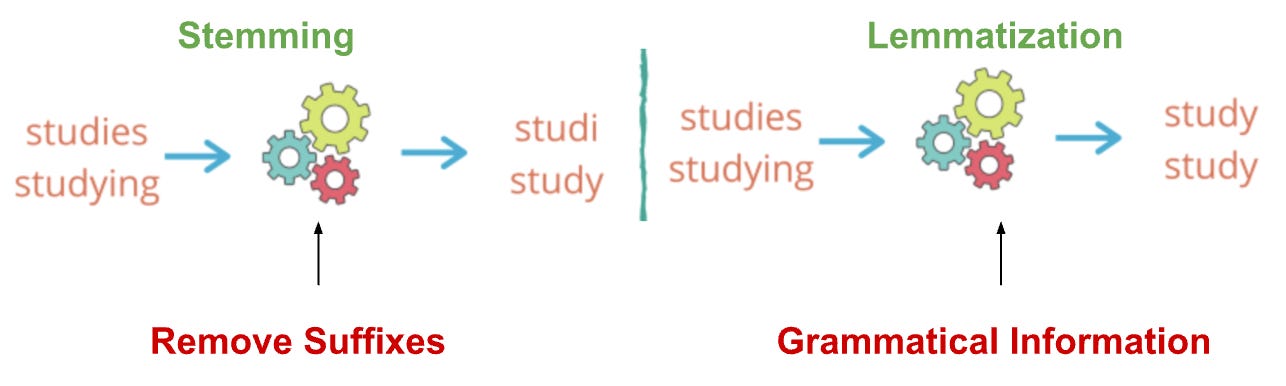
Stemming and Lemmatization: These are ways to convert words to their basic forms. Stemming is a more informal method that uses rules to find base forms, while lemmatization is a formal process that analyzes a word's structure using a dictionary. Libraries like spaCy and NLTK provide tools for stemming and lemmatization.

Sentence Segmentation: Breaking a big piece of text into meaningful sentence units. In English, this is often marked by a period, but it can be tricky. For instance, a period might indicate an abbreviation and not necessarily the end of a sentence. This becomes even more challenging in languages like ancient Chinese without a clear sentence-ending marker.
Stop Word Removal: Removing very common words, like "the," "a," and "an," that don't contribute much information to the text.
Tokenization: Breaking text into individual words and fragments. The result includes a word index and tokenized text where words are represented as numerical tokens for deep learning methods. Ignoring unimportant tokens can make language models more efficient.

Feature extraction
Most conventional machine-learning techniques work on the features – generally numbers that describe a document in relation to the corpus that contains it – created by either Bag-of-Words, TF-IDF, or generic feature engineering such as document length, word polarity, and metadata (for instance, if the text has associated tags or scores). More recent techniques include Word2Vec, GLoVE, and learning the features during the training process of a neural network.
Feature extraction serves as a vital step in transforming raw text into a format that machine learning algorithms can comprehend. These algorithms rely on numerical representations of language to perform tasks like text classification, sentiment analysis, and machine translation.
Conventional feature extraction techniques, such as Bag-of-Words (BoW) and TF-IDF, involve counting word frequencies or term weights to represent documents. While effective, these methods overlook the contextual relationships between words. To address this limitation, advanced techniques like Word2Vec and GLoVE have emerged. These methods capture semantic relationships between words by learning word embeddings, which are vector representations that preserve the meaning of words.Let's delve into each technique:
Bag-of-Words (BoW):
Imagine a document as a bag filled with words. BoW treats each document as a bag, counting the number of times each unique word appears. This approach provides a simple representation but lacks context.The table presented below illustrates the functioning of Bag of Words (BoW).

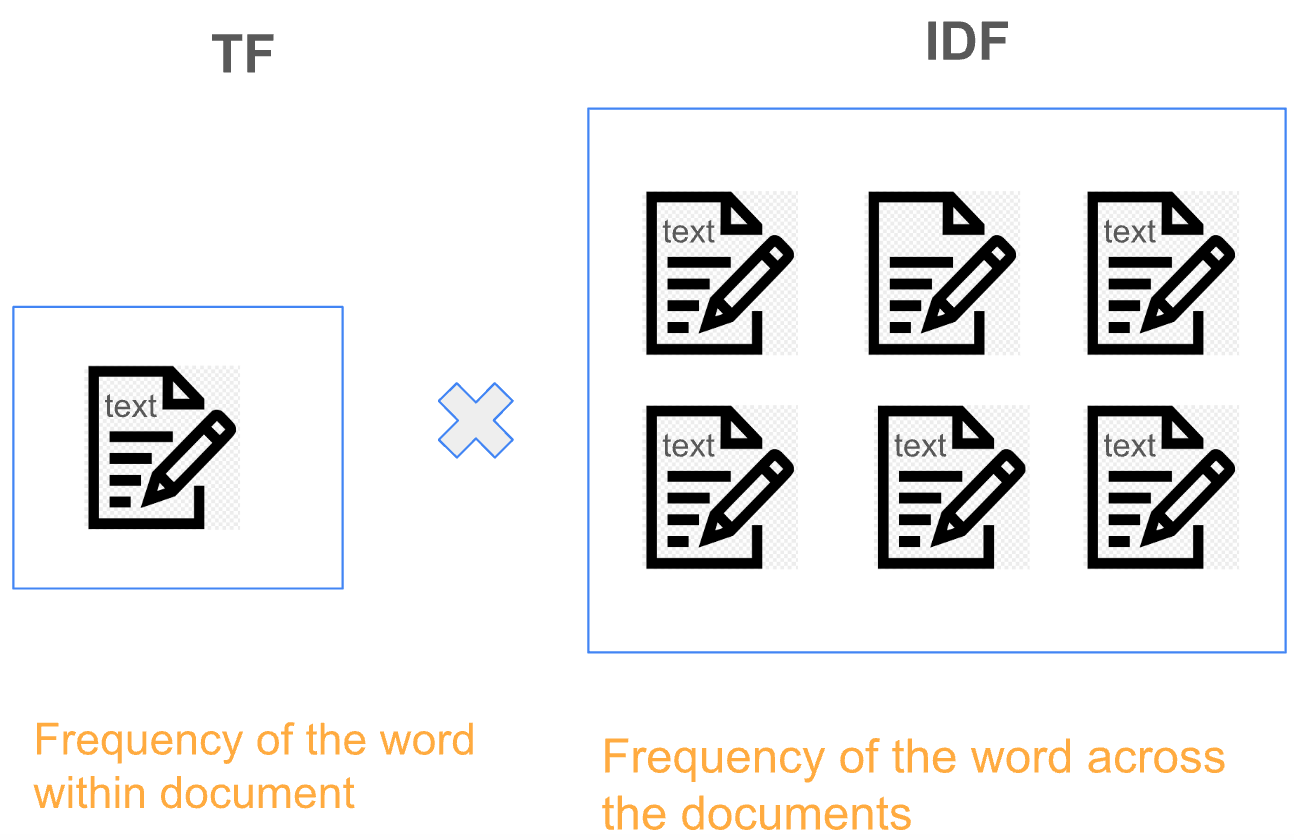
Term Frequency-Inverse Document Frequency (TF-IDF):
TF-IDF improves upon BoW by considering word frequency and document rarity. It assigns higher weights to words that appear frequently in a particular document but infrequently across the entire corpus, effectively capturing the importance of words.
Word2Vec:
In 2013, Word2Vec revolutionized the field of NLP by introducing neural networks to learn word embeddings directly from raw text. It offers two main variants: Skip-gram and Continuous Bag-of-Words (CBOW). Skip-gram predicts surrounding words given a target word, while CBOW predicts the target word from surrounding words. Both methods learn word embeddings that capture semantic relationships between words.

GLoVE (Global Vectors for Word Representation):
GLoVE shares similarities with Word2Vec but employs matrix factorization techniques rather than neural learning. It constructs a matrix based on global word-to-word co-occurrence counts, effectively capturing semantic relationships while avoiding the computational complexity of neural networks.
Modeling
After data is preprocessed, it is fed into an NLP architecture that models the data to accomplish a variety of tasks.
Numerical features extracted by the techniques described above can be fed into various models depending on the task at hand. For example, for classification, the output from the TF-IDF vectorizer could be provided to logistic regression, naive Bayes, decision trees, or gradient boosted trees. Or, for named entity recognition, we can use hidden Markov models along with n-grams.
Deep neural networks typically work without using extracted features, although we can still use TF-IDF or Bag-of-Words features as an input.
Language Models: In very basic terms, the objective of a language model is to predict the next word when given a stream of input words. Probabilistic models that use Markov assumption are one example:
Deep learning is also used to create such language models. Deep-learning models take as input a word embedding and, at each time state, return the probability distribution of the next word as the probability for every word in the dictionary. Pre-trained language models learn the structure of a particular language by processing a large corpus, such as Wikipedia. They can then be fine-tuned for a particular task. For instance, BERT has been fine-tuned for tasks ranging from fact-checking to writing headlines.
Challenges and Limitations of NLP: Technical hurdles and complexities
NLP is a complex field with a number of challenges, including:
Ambiguity: Human language is often ambiguous and can have multiple meanings. This can make it difficult for computers to understand the meaning of text correctly.
Word sense disambiguation: Words can have multiple meanings, and it can be difficult for computers to determine the correct meaning in a particular context.
Domain dependence: NLP models are often trained on data from a specific domain, such as news articles or technical documents. This can make it difficult for them to generalize to other domains.
Scalability: NLP models can be very large and complex, and it can be difficult to train and deploy them in real-world applications.
Complexities
Beyond technical hurdles above, NLP also faces a range of complexities that stem from the intricate nature of human language. These complexities require NLP models to handle a variety of linguistic phenomena and adapt to different cultural and social contexts.
Linguistic Phenomena: Human language is rich with linguistic phenomena that NLP models must be able to handle. These include idioms, sarcasm, figurative language, negation, and ellipsis, which can often be interpreted in multiple ways and require sophisticated linguistic analysis.
Cultural and Social Context: Understanding the nuances of culture and social context is crucial for accurate NLP applications. For instance, NLP systems used in customer service or marketing need to be aware of cultural sensitivities and adapt their language accordingly.
Ethical Considerations: The development and use of NLP systems raise ethical concerns around bias, discrimination, and privacy. NLP models should be carefully designed and trained to avoid perpetuating biases and respecting user privacy.
Addressing Challenges and Limitations
Overcoming these challenges and limitations requires continuous research and innovation in NLP. Researchers are exploring new techniques and algorithms to tackle ambiguity, handle unstructured data, and generalize to domain-specific language.
Model Complexity: Deep learning models have shown remarkable progress in NLP, but they often require large amounts of data and computational resources. Researchers are developing more efficient and scalable deep learning architectures to address these limitations.
Domain Adaptation: NLP models are increasingly being adapted to specific domains using techniques such as domain adaptation and transfer learning. These techniques aim to transfer the knowledge learned from a large general-purpose dataset to a smaller dataset of domain-specific text.
Human-In-the-Loop Systems: Incorporating human expertise and feedback into NLP systems can help improve accuracy and reduce bias. Human-in-the-loop systems can be used for tasks such as data cleaning, labeling, and error correction.
Explainable AI: Understanding how NLP models make decisions is critical for building trust and transparency. Explainable AI techniques aim to provide insights into the reasoning behind NLP models' predictions, allowing users to identify potential biases and areas for improvement.
Further Resources: Popular NLP Datasets, Libraries, and Online Courses
NLP and LLM Books
Hands-On Large Language Models by Jay Alammar and Maarten Grootendorst : This book provides a practical guide to working with large language models. It was released in December 2024 and is published by O'Reilly Media, Inc.
Foundation of Statistical Natural Language Processing by Christopher D Manning and Hinrich Schütze : This book explores the statistical approach to Natural Language Processing and helps users master the mathematics and linguistics needed. It focuses on statistical methods and techniques that have recently become popular.
Speech and Language Processing by Dan Jurafsky and James H Martin : This book provides a comprehensive introduction to the field of speech and language processing. It covers a wide range of topics including regular expressions and automata, morphology and finite-state transducers, computational phonology and text-to-speech, probabilistic models of pronunciation and spelling, HMMs and speech recognition, word classes and part-of-speech tagging, context-free grammars for English, parsing with context-free grammar, lexicalized and probabilistic parsing, language and complexity, semantic analysis, lexical semantics, machine translation.
Natural Language Understanding by James Allen. This book is another introductory guide to NLP and considered a classic. While it was published in 1994, it’s highly relevant to today’s discussions and analytics activities and lauded by generations of NLP researchers and educators. It introduces major techniques and concepts required to build NLP systems, and goes into the background and theory of each without overwhelming readers in technical jargon.
Handbook of Natural Language Processing by Nitin Indurkhya and Fred J. Damerau. This comprehensive, modern “Handbook of Natural Language Processing” offers tools and techniques for developing and implementing practical NLP in computer systems. There are three sections to the book: classical techniques (including symbolic and empirical approaches), statistical approaches in NLP, and multiple applications—from information visualization to ontology construction and biomedical text mining. The second edition has a multilingual scope, accommodating European and Asian languages besides English, plus there’s greater emphasis on statistical approaches. Furthermore, it features a new applications section discussing emerging areas such as sentiment analysis. It’s a great start to learn how to apply NLP to computer systems.
The Handbook of Computational Linguistics and Natural Language Processing by Alexander Clark, Chris Fox, and Shalom Lappin. Similar to the “Handbook of Natural Language Processing,” this book includes an overview of concepts, methodologies, and applications in NLP and Computational Linguistics, presented in an accessible, easy-to-understand way. It features an introduction to major theoretical issues and the central engineering applications that NLP work has produced to drive the discipline forward. Theories and applications work hand in hand to show the relationship in language research as noted by top NLP researchers. It’s a great resource for NLP students and engineers developing NLP applications in labs at software companies.
Deep Learning for Coders with fastai and PyTorch by Jeremy Howard and Sylvain Gugger : This book teaches deep learning concepts through practical coding exercises using the fastai and PyTorch libraries. It's designed for coders who want to understand and implement deep learning models.
Natural Language Processing with Transformers, Revised Edition by Lewis Tunstall, Leandro von Werra, and Thomas Wolf : Since their introduction in 2017, transformers have quickly become the dominant architecture for achieving state-of-the-art results in NLP. This book provides a comprehensive guide to implementing transformers in NLP.
Practical Natural Language Processing by Timothy Baldwin and Tristan Jehan. This book provides practical advice on how to implement NLP systems in real-world scenarios. It covers a wide range of topics, from basic techniques to advanced methods, and is suitable for both beginners and experienced professionals in the field.
Natural Language Processing with Transformers by Thomas Wolf. This book focuses on the use of transformers in NLP, offering a comprehensive introduction to the topic. It covers everything from the basics of transformers to their application in various NLP tasks.
Transformers for Natural Language Processing by Abhishek Thakur. This book dives deep into the principles and techniques behind transformers, making it a great resource for those interested in exploring this cutting-edge technology in the field of NLP.
“The Oxford Handbook of Computational Linguistics” by Ruslan Mitkov .This handbook describes major concepts, methods, and applications in computational linguistics in a way that undergraduates and non-specialists can comprehend. As described on Amazon, it’s a state-of-the-art reference to one of the most active and productive fields in linguistics. A wide range of linguists and researchers in fields such as informatics, artificial intelligence, language engineering, and cognitive science will find it interesting and practical. It begins with linguistic fundamentals, followed by an overview of current tasks, techniques, and tools in Natural Language Processing that target more experienced computational language researchers. Whether you’re a non-specialist or post-doctoral worker, this book will be useful.
“Foundations of Statistical Natural Language Processing” by Christopher Manning and Hinrich Schuetze.Another book that hails from Stanford educators, this one is written by Jurafsky’s colleague, Christopher Manning. They’ve taught the popular NLP introductory course at Stanford. Manning’s co-author is a professor of Computational Linguistics at the German Ludwig-Maximilians-Universität. The book provides an introduction to statistical methods for NLP and a decent foundation to comprehend new NLP methods and support the creation of NLP tools. Mathematical and linguistic foundations, plus statistical methods, are equally represented in a way that supports readers in creating language processing applications.
“Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit” by Steven Bird, Ewan Klein, and Edward Loper. This book is a helpful introduction to the NLP field with a focus on programming. If you want to have a practical source on your shelf or desk, whether you’re a NLP beginner, computational linguist or AI developer, it contains hundreds of fully-worked examples and graded exercises that bring NLP to life. It can be used for individual study, as a course textbook when studying NLP or computational linguistics, or in complement with artificial intelligence, text mining, or corpus linguistics courses. Curious about the Python programming language? It will walk you through creating Python programs that parse unstructured data like language and recommends downloading Python and the Natural Language Toolkit.
“Big Data Analytics Methods: Modern Analytics Techniques for the 21st Century: The Data Scientist’s Manual to Data Mining, Deep Learning & Natural Language Processing” by Peter Ghavami. This book might seem daunting to a NLP newcomer, but it’s useful as a comprehensive manual for those familiar with NLP and how big data relates in today’s world. It also works as a helpful reference for data scientists, analysts, business managers, and Business Intelligence practitioners. With more than a hundred analytics techniques and methods included, we think this will be a favorite for seasoned analytics practitioners. Chapters cover everything from machine learning to predictive modeling and cluster analysis. Data science topics including data visualization, prediction, and regression analysis, plus NLP-related fields such as neural networks, deep learning, and artificial intelligence are also discussed. These come with a broad explanation, but Peter goes into more detail about terminology and mathematical foundations, too.
"GPT-3: Building Innovative NLP Products Using Large Language Models" by Ben Awad. This book provides a hands-on approach to building innovative NLP products using GPT-3, one of the largest and most powerful language models available today.
Hands-On Generative AI with Transformers and Diffusion Models by Daniel Shiffman. This book offers a practical guide to working with generative AI, including the use of transformers and diffusion models. It's ideal for those who prefer learning by doing.
Representation Learning for Natural Language Processing by Zhiyuan Liu, Yankai Lin, and Maosong Sun. Published in 2021, this book offers an overview of recent advances in representation learning theory, algorithms, and applications for NLP. It covers everything from word embeddings to pre-trained language models, and is suitable for advanced undergraduate and graduate students, post-doctoral fellows, researchers, lecturers, and industrial engineers.
Online courses
Natural Language Processing (NLP)
"Natural Language Processing" by DeepLearning.AI on Coursera.
"Deep Learning for Natural Language Processing" from deeplearning.ai.
"Generative AI with Large Language Models" also by DeepLearning.AI on Coursera.
"Natural Language Processing with Classification and Vector Spaces" by DeepLearning.AI on Coursera.
"Natural Language Processing with Sequence Models" by DeepLearning.AI on Coursera.
"Natural Language Processing with Attention Models" by DeepLearning.AI on Coursera.
"Python for Everybody" by University of Michigan on Coursera.
"Natural Language Processing on Google Cloud" by Google Cloud on Coursera.
"Foundations of Natural Language Processing" by Stanford University on edX.
"Natural Language Processing" by University of California, Irvine on Udemy.
"Natural Language Processing with Python" by University of Helsinki on FutureLearn.
Large Language Models (LLM)
"Introduction to Large Language Models" by DeepLearning.AI on Coursera.
"Finetuning Large Language Models" by DeepLearning.AI on Coursera.
"Prompt Engineering for ChatGPT" by Vanderbilt University on Coursera.
"ChatGPT Prompt Engineering for Developers" by DeepLearning.AI on Coursera.
"Building Systems with the ChatGPT API" by DeepLearning.AI on Coursera.
"LangChain Chat with Your Data" by DeepLearning.AI on Coursera.
"ChatGPT Advanced Data Analysis" by Vanderbilt University on Coursera.
"Understanding Large Language Models" by Google Cloud on YouTube.
"Large Language Models" by DeepMind on YouTube.
"Understanding Large Language Models" by Stanford University on YouTube.
NLP Online Courses:
Find the link below to access the above courses:
https://www.coursera.org/courses?query=large%20language%20models
Conferences
Association for Computational Linguistics (ACL): This is one of the largest international conferences in computational linguistics, covering various areas including NLP and LLM.
Conference on Neural Information Processing Systems (NeurIPS): While not exclusively focused on NLP, many NLP and LLM researchers present their work at this conference.
Conference on Computational Natural Language Learning (CoNLL): CoNLL is a yearly conference organized by SIGNLL (ACL's Special Interest Group on Natural Language Learning). The focus of CoNLL is on theoretically, cognitively, and scientifically motivated approaches to computational linguistics. This includes computational learning theory and other techniques for theoretical analysis of machine learning models for NLP, models of language evolution and change, computational simulation and analysis of findings from psycholinguistic and neurolinguistic experiments, and more.
International Conference on Learning Representations (ICLR): This conference is a leading venue for machine learning research, and thus includes presentations on NLP and LLM.
Empirical Methods in Natural Language Processing (EMNLP): EMNLP is a major conference for empirical research in NLP, and it often features presentations on LLM.
NAACL HLT (Human Language Technology): This conference focuses specifically on NLP, and it's a good place to find up-to-date research in this field.
The Workshop on Deep Learning in Natural Language Processing (DeepNLP): As the name suggests, this workshop focuses on deep learning methods in NLP, which are often applied to LLM.
The Conference on Machine Learning and Knowledge Discovery in Databases (KDD): KDD includes sessions on NLP and LLM, making it another valuable resource.
AI In Finance Summit: This conference focuses on insights and technical use cases from AI specialists and data scientists in Financial Services. It covers topics such as the current AI landscape in finance, trends, the ROI of AI in financial services, AI advancements in fintech, and niche ML applications.
Arize:Observe: This is a one-day virtual summit dedicated to LLM observability. The conference includes presentations and panels from thought leaders and AI teams across industries. Topics covered range from performance monitoring and troubleshooting, data quality and troubleshooting, AI observability, explainability, ROI, and more.
NLP Summit: Organized by John Snow Labs, this summit is a global gathering of AI practitioners and researchers focusing on NLP technologies. The summit covers the latest developments in the field, including the application of LLMs.
NLP Datasets
Google's Books Corpus: A massive dataset of text from books and articles.
Common Crawl: A collection of text and code crawled from the internet.
Stanford Natural Language Inference (SNLI) Corpus: A dataset for evaluating natural language inference.
WordNet: A lexical database of English words and their relationships.
IMDB Reviews: This dataset consists of over 25,000 movie reviews from the IMDB website. It's perfect for binary sentiment classification tasks, where the goal is to classify a review as positive or negative.
Multi-Domain Sentiment Analysis Dataset: This dataset includes a vast array of Amazon product reviews. It's particularly useful for sentiment analysis tasks, where the aim is to determine whether a piece of text expresses a positive or negative sentiment.
Stanford Sentiment Treebank: This dataset contains over 10,000 movie reviews from Rotten Tomatoes. It's excellent for sentiment analysis tasks, especially when dealing with longer phrases.
Sentiment140: This dataset comprises over 160,000 tweets, formatted within six fields including tweet data, query, text, polarity, ID, and user. It's suitable for sentiment analysis tasks, particularly for analyzing sentiments expressed in social media posts.
20 Newsgroups: This dataset includes 20,000 documents that cover 20 newsgroups and subjects. It's ideal for text classification tasks, where the goal is to categorize a piece of text into one of several predefined classes.
Reuters News Dataset: This dataset, which appeared in 1987, has been labeled, indexed, and compiled for use in machine learning. It's excellent for text classification tasks, particularly for categorizing news articles into different topics.
ArXiv: This massive 270 GB dataset features all arXiv research papers in full text. It's suitable for text classification tasks, particularly for categorizing scientific papers into different research areas.
The WikiQA Corpus: This publicly-available Q&A dataset was initially compiled to aid in all open-domain question answering research. It's ideal for question answering tasks, where the goal is to generate a response given a question.
UCI’s Spambase: This dataset was created by a team at HP (Hewlett-Packard) to help create a spam filter. It contains a litany of emails previously labeled as spam by users. It's perfect for spam detection tasks, where the goal is to identify whether a piece of text is spam or not.
Yelp Reviews: This Yelp dataset features 8.5M+ reviews of over 160,000 businesses. It also has 200,000+ pictures and spans across 8 major metropolitan areas. It's suitable for sentiment analysis tasks, particularly for analyzing sentiments expressed in customer reviews.
Here are some of the latest datasets used for training Large Language Models (LLMs):
1. RefinedWeb: This is a massive corpus of deduplicated and filtered tokens from the Common Crawl dataset. With more than 5 trillion tokens of textual data, of which 600 billion are made publicly available, it was developed as an initiative to train the Falcon-40B model with smaller-sized but high-quality datasets.
2. The Pile: This is an 800 GB corpus that enhances a model’s generalization capability across a broader context. It was curated from 22 diverse datasets, mostly from academic or professional sources. The Pile was instrumental in training various LLMs, including GPT-Neo, LLaMA, and OPT.
3. Starcoder Data: This is a programming-centric dataset built from 783 GB of code written in 86 programming languages. It also contains 250 billion tokens extracted from GitHub and Jupyter Notebooks. Salesforce CodeGen, Starcoder, and StableCode were trained with Starcoder Data to enable better program synthesis.
4. BookCorpus: This dataset turned scraped data of 11,000 unpublished books into a 985 million-word dataset. It was initially created to align storylines in books to their movie interpretations. The dataset was used for training LLMs like RoBERTa, XLNET, and T5.
5. ROOTS: This is a 1.6TB multilingual dataset curated from text sourced in 59 languages. Created to train the BigScience Large Open-science Open-access Multilingual (BLOOM) language model. ROOTS uses heavily deduplicated and filtered data from Common Crawl, GitHub Code, and other crowdsourced initiatives..
6. Wikipedia: The Wikipedia dataset is curated from cleaned text data derived from the Wikipedia site and presented in all languages. The default English Wikipedia dataset contains 19.88 GB of vast examples of complete articles that help with language modeling tasks. It was used to train larger models like Roberta, XLNet, and LLaMA.
7.Databricks-dolly-15k: This is a dataset for LLM finetuning that features >15,000 instruction-pairs written by thousands of DataBricks employees. It is similar to those used to train systems like InstructGPT and ChatGPT.
8. OpenAssistant Conversations: This is another dataset for fine tuning pretraining LLMs on a collection of ChatGPT assistant-like dialogues that have been created and annotated by humans, encompassing 161,443 messages in 35 diverse languages, along with 461,292 quality assessments. These are organized in more than 10,000 thoroughly annotated conversation trees.
9. RedPajama: This is an open-source dataset for pretraining LLMs similar to LLaMA Meta's state-of-the-art LLaMA model. The goal of this project is to create a capable open-source competitor to the most popular LLMs, which are currently closed commercial models or only partially open [Source 4](https://magazine.sebastianraschka.com/p/ahead-of-ai-8-the-latest-open-source).
10. Pythia: This is an 800GB dataset of diverse texts for 300 B tokens (~1 epoch on regular Pile, ~1.5 epochs on deduplicated Pile). The recent instruction-finetuned open-source Dolly v2 LLM model used Pythia as the base (foundation) model.

NLP Libraries

AllenNLP: This is an Apache 2.0 NLP research library, built on PyTorch, for developing state-of-the-art deep learning models on a wide variety of linguistic tasks. It provides a broad collection of existing model implementations that are well documented and engineered to a high standard, making them a great foundation for further research. AllenNLP offers a high-level configuration language to implement many common approaches in NLP, such as transformer experiments, multi-task training, vision+language tasks, fairness, and interpretability. This allows experimentation on a broad range of tasks purely through configuration, so you can focus on the important questions in your research.
NLTK: NLTK — the Natural Language Toolkit — is a suite of open-source Python modules, data sets, and tutorials supporting research and development in Natural Language Processing. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries.
NLP Architect: NLP Architect is an open-source Python library for exploring state-of-the-art deep learning topologies and techniques for optimizing Natural Language Processing and Natural Language Understanding Neural Networks. It’s a library designed to be flexible, easy to extend, allowing for easy and rapid integration of NLP models in applications, and to showcase optimized models.
PyTorch-NLP: PyTorch-NLP is a library of basic utilities for PyTorch NLP. It extends PyTorch to provide you with basic text data processing functions.
John Snow Labs: John Snow Labs' NLP & LLM ecosystem include software libraries for state-of-the-art AI at scale, Responsible AI, No-Code AI, and access to over 20,000 models for Healthcare, Legal, Finance, and Visual NLP.
PyNLPl: Pronounced as ‘pineapple,’ PyNLPl is a Python library for Natural Language Processing. It contains a collection of custom-made Python modules for Natural Language Processing tasks. One of the most notable features of PyNLPl is that it features an extensive library for working with FoLiA XML (Format for Linguistic Annotation). PyNLPl is segregated into different modules and packages, each useful for both standard and advanced NLP tasks. While you can use PyNLPl for basic NLP tasks like extraction of n-grams and frequency lists, and to build a simple language model, it also has more complex data types and algorithms for advanced NLP tasks.
Stanford CoreNLP: Stanford CoreNLP is a Java library for NLP processing. It provides a set of natural language analysis tools that include token and sentence boundaries, parts of speech, named entities, numeric and time values, dependency and constituency parses, coreference, sentiment, quote attributions, and relations. It's a comprehensive library for NLP tasks and is widely used in academia and industry.
TensorFlow: TensorFlow is an open-source library developed by Google Brain Team. It's used for numerical computation, particularly well suited for large-scale Machine Learning. It provides a flexible platform for defining and running machine learning algorithms. It supports a wide range of tasks including computer vision, natural language processing, and more.
Hugging Face Transformers: Hugging Face Transformers is a state-of-the-art Natural Language Processing library for TensorFlow 2.0 and PyTorch. It provides thousands of pre-trained models to perform tasks on texts such as classification, information extraction, generation, etc. It's widely used in the field of NLP due to its ease of use and the availability of pre-trained models.
Keras: Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano. It allows for easy and fast prototyping and supports both convolutional networks and recurrent networks, as well as combinations of the two.
Pattern: Pattern is a web mining module for Python. It includes tools for natural language processing, machine learning, and graph theory. It's used for tasks such as part-of-speech tagging, named entity recognition, sentiment analysis, text classification, and topic modeling.
Polyglot: Polyglot is a Python library that implements various algorithms for natural language processing. It supports a wide range of languages and tasks, including morphological analysis, syntax parsing, machine translation, and more.
gensim: gensim is a Python library for topic modelling, document indexing, and similarity retrieval with large corpora. It's used for creating vector space models, performing topic modelling, and building similarity retrieval systems.

Summary
This article introduces Natural Language Processing (NLP), a pivotal field in computer science that bridges the gap between computers and human language, enabling machines to understand, generate, translate, and even write human-quality text. NLP has seen remarkable advancements, making it possible for computers to comprehend programming languages, biological sequences, and even the nuances of human language. The article delves into the fundamental concepts of NLP, such as tokenization, stemming, and tagging, and explores its applications in tasks like machine translation, sentiment analysis, and text summarization.It also offers resources for further exploration, including popular NLP datasets, libraries, and online courses. By the end of this article, now you will have a grasp of the components of an NLP system and the complexities involved in developing these systems.
Quiz Question
What is the primary purpose of Natural Language Processing (NLP)?
A) To process binary data
B) To enhance user experience on websites
C) To enable computers to understand and generate human language
D) To optimize database performance
Which of the following is NOT a common task in NLP?
A) Sentiment analysis
B) Machine translation
C) Speech recognition
D) Image captioning
What is the process of breaking down text into smaller pieces called?
A) Parsing
B) Tagging
C) Tokenization
D) Stemming
What challenge does NLP face due to the ambiguity of human language?
A) Inability to understand context
B) Inability to handle synonyms
C) Inability to understand slang
D) All of the above
Correct Answers:
C
D
C
D