

Deploying a RAG Application in AWS Lambda using Docker and ECR
Lambda — ECR — Docker — LangChain — OpenAI

Lambda — ECR — Docker — LangChain — OpenAI
Deploying a RAG (Retrieval-Augmented Generation) application in AWS Lambda using Docker and Amazon Elastic Container Registry (ECR) with LangChain involves several steps and services. This article will explain each service and how they work together in an integrated way, followed by the steps to deploy it.
Here is the link to the complete tutorial on Deploying RAG in AWS.
Before proceeding further, I would like to kindly suggest that you take some time to read and watch the tutorial titled “Build and Deploy LLM Application in AWS.” This tutorial can provide you with a solid foundation on Lambda LLM application deployment.
Build and Deploy LLM Application in AWS
AWS Lambda — BedRock — LangChainmedium.com
Services Overview
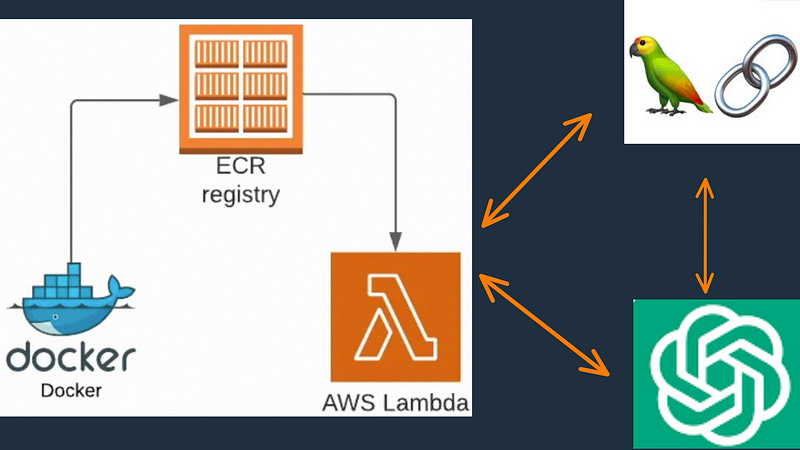
AWS Lambda: A serverless compute service that runs your code in response to events and automatically manages the underlying compute resources for you. It allows you to run code without provisioning or managing servers.
- Amazon ECR: A fully-managed container registry that makes it easy for developers to store, manage, and deploy Docker container images. It’s integrated with Amazon ECS and AWS Fargate, simplifying your development to production workflow.
- Docker: A platform that uses containerization to package up an application with all of the parts it needs, such as libraries and other dependencies, and ship it all out as one package. This ensures that the application runs quickly and reliably on any server.
Dowload Link: https://www.docker.com/products/docker-desktop/
- LangChain: A framework for building and deploying language models, providing tools for document loading, vector storage, embeddings, and more. It’s used here to facilitate the deployment of the RAG model.
Integration and Deployment Steps
Prepare Your Environment: Ensure you have the AWS CLI installed and configured, Docker installed, and Python 3.11 or later installed and configured. You’ll also need an active AWS account with the necessary permissions.
Download Link: https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html
2. Create a Dockerfile: This file defines the environment in which your Lambda function will run. It starts from a base image provided by AWS (`public.ecr.aws/lambda/python:3.12`) and copies your application code and dependencies into the image. It also installs any necessary Python packages from a `requirements.txt` file as below:
langchain_community
boto3==1.34.37
numpy
langchain
langchainhub
langchain-openai
chromadb
bs4
tiktoken
openai# Use the AWS base image for Python 3.12
FROM public.ecr.aws/lambda/python:3.12
# Install build-essential to get the C++ compiler and other necessary tools
RUN microdnf update -y && microdnf install -y gcc-c++ make
# Copy requirements.txt
COPY requirements.txt ${LAMBDA_TASK_ROOT}
# Install the specified packages
RUN pip install -r requirements.txt
# Copy function code
COPY lambda_function.py ${LAMBDA_TASK_ROOT}
# Set the permissions to make the file executable
RUN chmod +x lambda_function.py
# Set the CMD to your handler
CMD [ "lambda_function.lambda_handler" ]3. Build and Push Your Docker Image to Amazon ECR: Use the AWS CLI to create a repository in ECR, build your Docker image, and push it to the repository. This step requires permissions to interact with ECR and S3.
aws ecr create-repository - repository-name my-rag-lambda
docker build -t my-test-lambda .
docker tag my-rag-lambda:latest <aws_account_id>.dkr.ecr.<region>.amazonaws.com/my-test-lambda:latest
docker push <aws_account_id>.dkr.ecr.<region>.amazonaws.com/my-test-lambda:latest4. Create a Lambda Function: In the AWS Lambda console, create a new function using the container image option. Specify the URI of the image in ECR as the image source.
5. Configure Your Lambda Function: Set the necessary environment variables, such as `OPENAI_API_KEY` for LangChain, and configure any other settings as needed.
6. Test Your Lambda Function: Invoke your Lambda function to test it. You can do this from the AWS Lambda console or using the AWS CLI. Ensure that the function is correctly processing inputs and generating outputs as expected.
Implementation
Below code is designed to deploy a Retrieval-Augmented Generation (RAG) model using AWS Lambda, Docker, and Amazon ECR, with LangChain for language model deployment.
Environment Setup
First, imports necessary libraries and sets up the environment:
import boto3
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_community.embeddings import OpenAIEmbeddings
from langchain_community.chat_models import ChatOpenAI
from langchain_text_splitters import RecursiveCharacterTextSplitter
import os
# Retrieve the OpenAI API key from environment variables
OPENAI_API_KEY = os.environ['OPENAI_API_KEY']
print(OPENAI_API_KEY)- boto3: The AWS SDK for Python, allowing Python developers to write software that makes use of services like Amazon S3, Amazon EC2, and others.
- bs4: Beautiful Soup, a library for pulling data out of HTML and XML files.
- LangChain: A framework for building and deploying language models, providing tools for document loading, vector storage, embeddings, and more.
- Environment Variables: The code retrieves the `OPENAI_API_KEY` from the environment variables, which is crucial for accessing OpenAI’s API.
Data Loading and Processing
The `load_data` function is responsible for loading, chunking, and indexing the contents of a web page:
def load_data():
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
return retriever- WebBaseLoader: Loads documents from web paths, using Beautiful Soup to parse and extract specific elements.
- RecursiveCharacterTextSplitter: Splits documents into chunks based on character count and overlap.
- Chroma: Creates a vector store from the split documents, using OpenAI embeddings for vectorization.
- Retriever: A retriever object that can be used to retrieve relevant documents based on queries.
Response Generation
The `get_response` function generates a response to a given query using the RAG model:
def get_response(query):
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
retriever = load_data()
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
return rag_chain.invoke(query)- hub.pull: Retrieves a prompt from LangChain’s hub.
- ChatOpenAI: Initializes a chat model with GPT-3.5 Turbo.
- RunnablePassthrough: A component that passes the input directly to the next component in the chain.
- StrOutputParser: Parses the output of the RAG model into a string format.
AWS Lambda Handler
Finally, the `lambda_handler` function is the entry point for AWS Lambda, which receives an event and context, processes the query, and returns a response:
def lambda_handler(event, context):
query = event.get("question")
response = get_response(query)
print("response:", response)
return {"body": response, "statusCode": 200}Event and Context: AWS Lambda passes an event object and a context object to the handler. The event object contains information about the triggering event, and the context object contains information about the runtime environment.
Query Processing: The function extracts the query from the event, generates a response using the `get_response` function, and prints the response and returns a response object containing the generated response and a status code of 200, indicating success.
Conclusion
Deploying a RAG model in AWS Lambda using Docker and ECR with LangChain involves preparing your environment, creating a Dockerfile, building and pushing your Docker image to ECR, creating a Lambda function, configuring it, and testing it. This process leverages the serverless capabilities of AWS Lambda, the containerization benefits of Docker, and the language model deployment capability provided by LangChain.
Connect with me on Linkedin
Find me on Github
Visit my technical channel on Youtube
Thanks for Reading!